自炊(スキャナを使った紙文書の電子化)をしている人はたくさんいると思うが、実際やってみるといろいろコツが要求される。
そこで、これから始めようという人の参考になるよう、私自身のやり方をまとめてみることにする。
■目的の明確化
自炊でまず大事なのは、目的をはっきりさせること。
私の場合、溜め込んだ本や雑誌、新聞の切り抜きなどを電子化して、全文検索とテキストの再利用を可能にすることが目的だった。実際、確かに読んだ記憶があるのにどの雑誌のどの号に載っていたか分からないとか、引用のためにテキストを打ち直すのが大変、といったことがたびたびあって、自炊以外に解決手段がなくなっていたのだ。
この目的が違っていると私のやり方は参考にならないと思うので念のため。
■機材の準備
フラットベッドスキャナでは現実的に自炊は無理で、どうしても紙送り機構のあるドキュメントスキャナが必要になる。私の場合、ScanSnap S1300(既に後継機種のS1300iが出ているので、今から買うならこちら)を使っている。これか、上位機種のS1500あたりが代表的な選択肢だろう。
S1300iが2万円程度なのに対して、S1500は3万6千円程度する。しかし、読み込み速度が数倍違うので、何百冊もある書籍を一気に電子化したい、といった場合はS1500を選んだほうがよい。でないと最悪買い直すようなことにもなりかねない。
私の場合は、設置場所が狭かったことと、必要に応じて少しずつ電子化するつもりだったことからS1300にした。S1300はテイッシュ箱くらいの大きさしかないので、まず設置場所に困ることはない。
あと、普通ならスキャナに加えて裁断機を用意するところだが、私の場合は、(1)ちゃんとした裁断機はそれなりの値段がする、(2)裁断機の置き場所と作業場所に困る、(3)猫がいるのでイタズラして怪我でもしないか心配、という理由で、いまだに買っていない。実際、以下で説明するように、普通の書籍や雑誌程度ならカッターとハサミで十分処理できる。
■ScanSnap Managerの設定
ScanSnapをパソコンに接続したら、付属ソフトのScanSnap Managerの設定を行う。私の場合は次のような設定をしている。

連携アプリとしてScanSnap Organizerを指定。

読み取りモードはスーパーファインのグレー(300dpi)。電子化した文書の読みやすさと文字認識の認識率を考慮すると、この程度にしておいたほうがよい。あと、「継続読み取り」を有効にしておく。
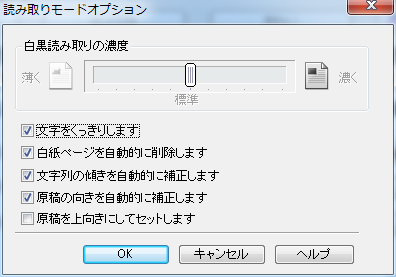
読み取りモードのオプションはこんな感じ。

ファイル形式はもちろんPDF。
ここで、「検索可能なPDFにします」はチェックしないでおく。これをチェックすると読み取り終了後に自動的に文字認識が始まるのだが、認識処理中は次の読み込みができないので、かえって能率が下がってしまう。
■文書をバラす
ここからが自炊作業の本番。ここでは、小林英夫著『日本軍政下のアジア』(岩波新書)をサンプルに作業手順を説明する。

道具として使うのは前記のとおり普通のカッターとハサミだけ。

まずカバーを外し、表紙を剥がす。

だいたい50〜60ページごとに、背面の糊付け部分にカッターで切れ目を入れて、ページを外しやすくしておく。

あとは、5枚程度ごとにページを外して、糊付け部分から数ミリをハサミで切り取り、バラしていく。
バラしたページは10枚単位にまとめておく。最終ページが20、40、60、と切りの良い数字になるようにしておくと分かりやすい。岩波新書のように目次に独立したページが振られている場合、目次部分は分けておく。
(実際には最初に全部バラしてしまうより、バラしながら並行にスキャン作業をしたほうが効率的。)
■スキャン作業
文書をバラしたら、いよいよスキャン作業。まとめておいた10枚を1単位としてスキャンを行う。(S1300の場合、20枚入れると途中で詰まる確率がかなり高くなるので、やめたほうが良い。)
10枚分のページをスーパーファインモードで読み込むスピードがどの程度かは、次の動画を見て欲しい。(後継機種のS1300iはこれより25%程度速くなっているはず。)
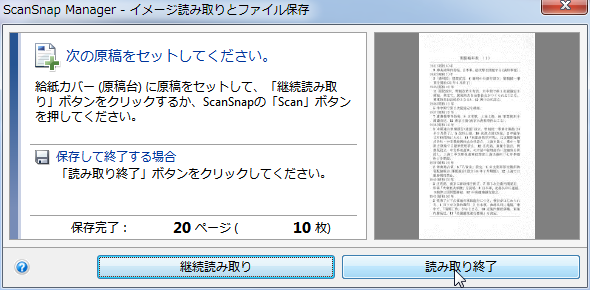
1単位のスキャンが終わると、ScanSnap Managerの表示は上のようになる。ここで、枚数表示がセットした1単位の枚数と一致していることを必ず確認してから「読み取り終了」をクリックする。(ページ数の表示は、途中で空白ページがスキップされるとその分少なくなるので、枚数の方で確認する。)
もしこの表示がセットした枚数に満たない場合、それは途中でページが重なって送られてしまったことを意味している。多重送りでページが欠けてしまったことに気づかないで元の文書を捨ててしまうと欠けたページは復元できなくなってしまうので、この確認は非常に重要。多重送りが発生した場合、読み取ったデータは捨てて、もう一度その1単位をスキャンする。

「読み取り終了」を押すと、生成されたPDFファイルが順次ScanSnap Organizerのフォルダに送られ、上のような表示になる。
このフォルダに置かれたファイルは、放っておいてもパソコンの空き時間を利用して勝手に文字認識されるが、待ちきれない場合は次のようにファイルを選択して「検索可能なPDFに変換」する。

文字認識済みのファイルには「A」マークが表示され、全部終了すると次のような状態になる。

■PDFファイルの結合
以上でスキャン作業は終了だが、このままだと一冊の本が多数のPDFファイルに分かれてしまっていて扱いにくいので、ファイルの結合を行う。
私の場合、結合にはフリーソフトのConcatPDFを使っている。非常にシンプルなインターフェースで、ページの並べ替えや結合・削除が簡単にできる。
サンプルとして使った『日本軍政下のアジア』(229ページ)の場合、文字認識後のファイルサイズは42.3MBとなった。この程度なら、数百冊電子化しても、今時のパソコンのストレージ容量からしたら問題にはならないだろう。
■その他
64bit版Windows(最近のパソコンに入っているWindows7は大抵これ)の場合、そのままではPDFファイルの全文検索ができないという問題がある。これではせっかく紙文書を電子化しても、有用性が半減してしまう。
この問題を解決するには、PDFファイルからテキストを抜き出すフィルタであるPDF iFilterというソフトを導入する必要がある。導入方法については、こちらなどを参照して欲しい。
【2014/11/23追記】
ScanSnapのようなドキュメントスキャナを手入れする際、大事な注意事項がある。それは、エアスプレーやブロアーなどで埃を吹き飛ばさないことだ。これはマニュアルにもちゃんと書いてある。
カメラを手入れするのと同じような感覚でついやってしまいがちなのだが、吹き飛ばした埃がセンサー部に入り込むと、スキャンした画像に黒い線が入るようになる。しかも、一度入り込んだ埃は容易に取れない。
清掃する際には、専用のクリーニングワイプを使うか、刷毛状のもので埃を外側に払うようにするとよい。
【2015/10/3追記】
OSをWindows10にアップグレードしたところ、ScanSnap Organizerへの登録時に、「検索可能にするPDFファイルの一覧への登録に失敗しました。」というエラーが表示されるようになってしまった。現象としては、メッセージは出るが実際にはデータは登録されている。ただし、そのまま放っておいてもOCRはされず、手動で実行しなければならない。
ScanSnap ManagerとScanSnap Organizerを一度アンインストールし、再インストールしてみたところ、問題は解決した。(単に最新版にアップデートするだけではダメ。)Windows10への移行でソフトの実行に不具合が生じた場合、インストールし直すことで解決することが多いようだ。
 FI-S1300B")
富士通 FUJITSU ScanSnap S1300i (A4/両面/バスパワー駆動) FI-S1300B
- 出版社/メーカー: 富士通
- 発売日: 2015/02/06
- メディア: Personal Computers
- この商品を含むブログを見る
 FI-IX500A")
富士通 FUJITSU ScanSnap iX500 (A4/両面/Wi-Fi対応) FI-IX500A
- 出版社/メーカー: 富士通
- 発売日: 2015/02/06
- メディア: Personal Computers
- この商品を含むブログ (2件) を見る
 FI-SV600A")
富士通 FUJITSU ScanSnap SV600 (A3/片面/オーバーヘッド読取方式) FI-SV600A
- 出版社/メーカー: 富士通
- 発売日: 2015/02/06
- メディア: Personal Computers
- この商品を含むブログ (5件) を見る